 By
By How does a search engine work? Let’s find out – by building one!
Search engines have become the gateway to the modern web. How often do you know exactly which page you want, but you search for it anyway, rather than typing the URL into your web browser?

Like many great machines, the simple search engine interface - a single input box - hides a world of technical magic tricks. When you think about it, there are a few major challenges to overcome. How do you collect all the valid URLs in existence? How do you guess what the user wants and return only the relevant pages, in a sensible order? And how do you do that for 130 Trillion pages faster than a human reaction time?
I’ll be some way closer to understanding these problems when I’ve built a search engine for myself. I’ll be using nothing but Python (even for the UI) and my code will be simple enough to include in this blog post.
You can copy the final version, try it out, and build on it yourself:
There will be three parts to this.
-
First, I’m going to build a basic search engine that downloads pages and matches your search query against their contents. (That’s this post)
-
Then I’m going to implement Google’s PageRank algorithm to improve the results. (See Part 2)
-
Finally, I’ll play with one of computer science’s powertools - indexing - to speed up the search and make the ranking even better. (See Part 3)
Collecting URLs
Let’s start building a machine that can download the entire web.
I’m going to a build a web crawler that iteratively works its way through the web like this:
- Start at a known URL
- Download the page
- Make a note of any URLs it contains
- GOTO 1 (for the new URLs I’ve found)
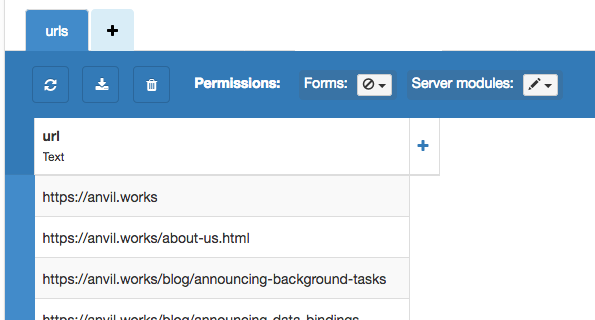
I need a known URL to start with. I’ll allow webmasters and other good citizens to submit URLs they know about. I’ll store them in a database (I’m using Anvil’s Data Tables) and if I know the URL already, I won’t store it twice.
@anvil.server.callable
def submit_url(url):
url = url.rstrip('/') # URLs with and without trailing slashes are equivalent
if not app_tables.urls.get(url=url):
app_tables.urls.add_row(url=url)I’ve also made it possible to submit sitemaps, which contain lists of many URLs (see our Background Tasks tutorial for more detail.) I’m using BeautifulSoup to parse the XML.
from bs4 import BeautifulSoup
@anvil.server.callable
def submit_sitemap(sitemap_url):
response = anvil.http.request(sitemap_url)
soup = BeautifulSoup(response.get_bytes())
for loc in soup.find_all('loc'):
submit_url(loc.string)If I submit the Anvil sitemap, my table is populated with URLs:
I’m in good company by allowing people to submit URLs and sitemaps for crawling - Google Search Console does this. It’s one way of avoiding my crawler getting stuck in a local part of the web that doesn’t link out to anywhere else.
Stealing shamelessly from Google Search Console, I’ve created a webmaster’s console with ‘submit’ buttons that
call my submit_url and submit_sitemap functions:
def button_sitemap_submit_click(self, **event_args):
"""This method is called when the button is clicked"""
self.label_sitemap_requested.visible = False
anvil.server.call('submit_sitemap', self.text_box_sitemap.text)
self.label_sitemap_requested.visible = True
def button_url_submit_click(self, **event_args):
"""This method is called when the button is clicked"""
self.label_url_requested.visible = False
anvil.server.call('submit_url', self.text_box_url.text)
self.label_url_requested.visible = TrueCrawling
Now that I know some URLs, I can download the pages they point to. I’ll create a Background Task that churns through my URL list making requests:
@anvil.server.background_task
def crawl():
for url in app_tables.urls.search():
# Get the page
try:
response = anvil.http.request(url)
html = response.get_bytes().decode('utf-8')
except:
# If the fetch failed, just try the other URLs
continue
row = app_tables.pages.get(url=url) or app_tables.pages.add_row(url=url)
row['html'] = htmlBecause it’s a Background Task, I can fire off a crawler and download all the pages I know about in the background without blocking the user’s interaction with my web app.
That’s all very well, but it doesn’t really crawl yet. The clever thing about a web crawler is how it follows links between pages. The web is a directed graph – in other words, it consists of pages with one-way links between them. That’s why it’s such a wonderful information store - if you’re interested in the subject of one page, you’re likely to be interested in the subjects of pages it links to. If you’ve ever been up ’til dawn in the grip of a Wikipedia safari, you’ll know what I’m talking about.
So I need to find the URLs in the pages I download, and add them to my list. BeautifulSoup, the brilliant HTML/XML parser, helps me out again here.
I also record which URLs I found on each page - this will come in handy when I implement PageRank.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)
# Parse out the URLs
for a in soup.find_all('a', href=True):
submit_url(a['href'])
# Record the URLs for this page
page['forward_links'] += a['href']While I’m at it, I’ll grab the page title to make my search results a bit more human-readable:
# Parse out the title from the page
title = str(soup.find('title').string) or 'No Title'The crawler has become rather like the classic donkey following a carrot: the further it gets down the URL list, the more URLs it finds, so the more work it has to do. I visualised this by plotting the length of the URL list alongside the number of URLs processed.
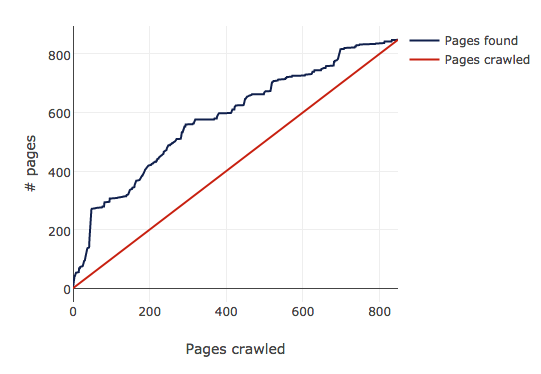
The list grows initially, but the crawler eventually finds all the URLs and the lines converge. It converges because I’ve restricted it to https://anvil.works (I don’t want to denial-of-service anybody’s site by accident.) If I had it crawling the open web, I imagine the lines would diverge forever - pages are probably being added faster than my crawler can crawl.
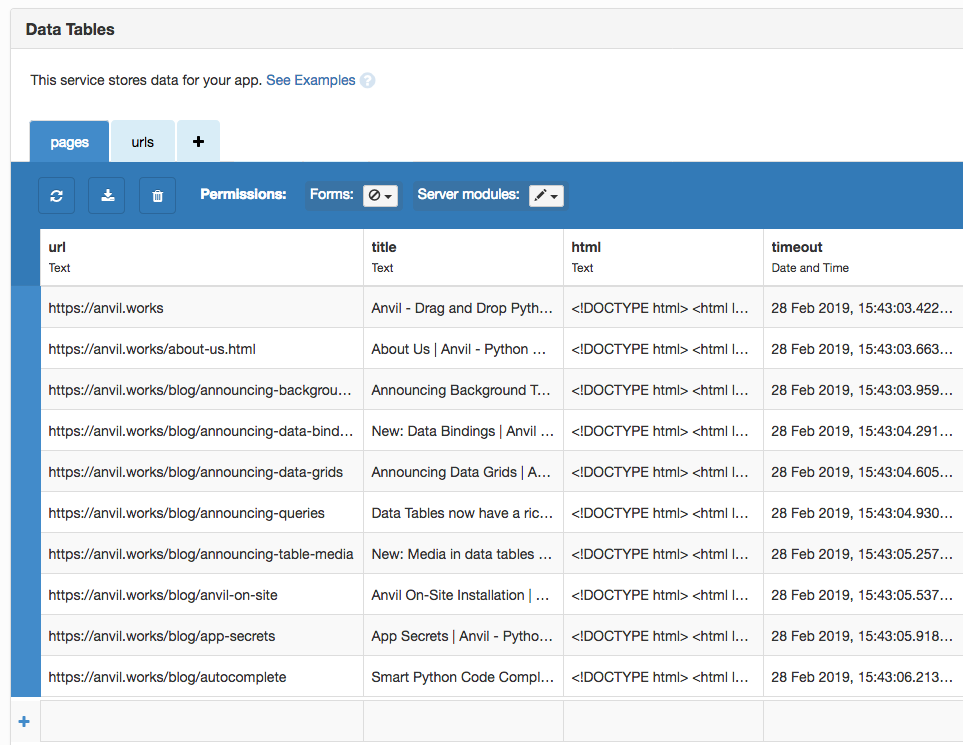
By the time it has finished, there’s a nice crop of page data waiting for me in the pages table.
Making a search
Time to implement search. I’ve thrown together the classic “input box and button” UI using the drag-and-drop editor. There’s also a Data Grid for listing the results, which gives me pagination for free. Each result will contain the page title and a link.
The most basic search algorithm would just break the query into words and return pages that contain any of those words. That’s no good at all, and I can do better straight away.
I’ll remove words that are too common. Let’s say a user enters ‘how to build a web app’. If a page happens to contain exactly the text ‘how to build a web app’, it will be returned. But they would also get pages containing the text ‘how to suckle a lamb’.
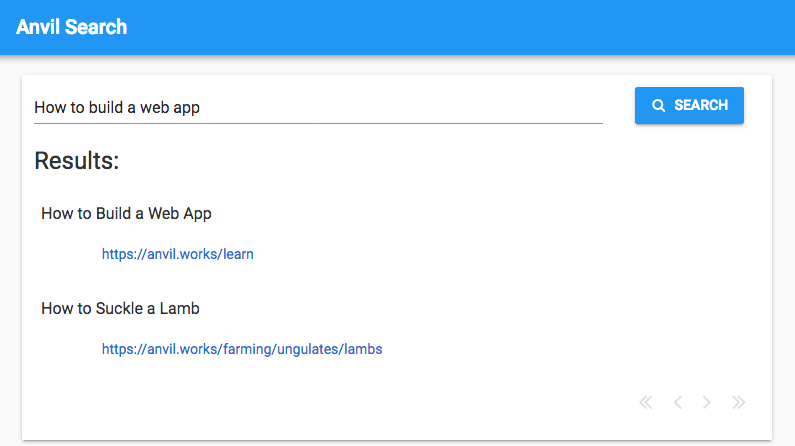
So I’ll remove words like ‘how’ and ’to’. In the lingo, these are called stop words.
I’ll include words that are closely related to those in the query. The search for ‘how to build a web app’ should probably return pages with ‘application builder’, even though neither of those words are exactly in the query.
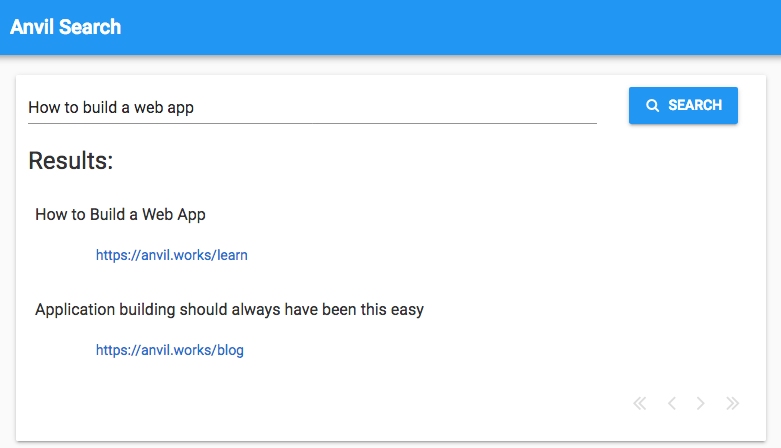
In the lingo, this is called stemming.
Both of these requirements are met by Anvil’s full_text_match operator, so I can get a viable search running right away:
# On the server:
@anvil.server.callable
def basic_search(query):
return app_tables.pages.search(html=q.full_text_match(query))# On the client:
def button_search_click(self, **event_args):
"""This method is called when the button is clicked"""
self.repeating_panel_1.items = anvil.server.call('basic_search', self.text_box_query.text)Later on we’ll talk about indexing and tokenization, which gets to the nuts and bolts of how to optimise a search. But for now, I have a working search engine. Let’s try some queries.
Test queries
For each stage in its development, I’m going to run three queries to see how the results improve as I improve my ranking system. Each query is chosen to reflect a different type of search problem.
I’ll only look at the first page of ten results. Nobody ever looks past the first page!
(If you’re wondering why all the results are from the same site, bear in mind that I’ve restricted my crawler to https://anvil.works to avoid getting my IP address quite legitimately blocked by anti-DoS software, and to keep my test dataset to a manageable size.)
‘Plots’
‘Plots’ is a fairly generic word that you would expect to show up all over the place in technical writing. The challenge is to return the pages that are specifically about plotting, rather than those that just use the word in passing.
When I search for ‘plots’, I get this:
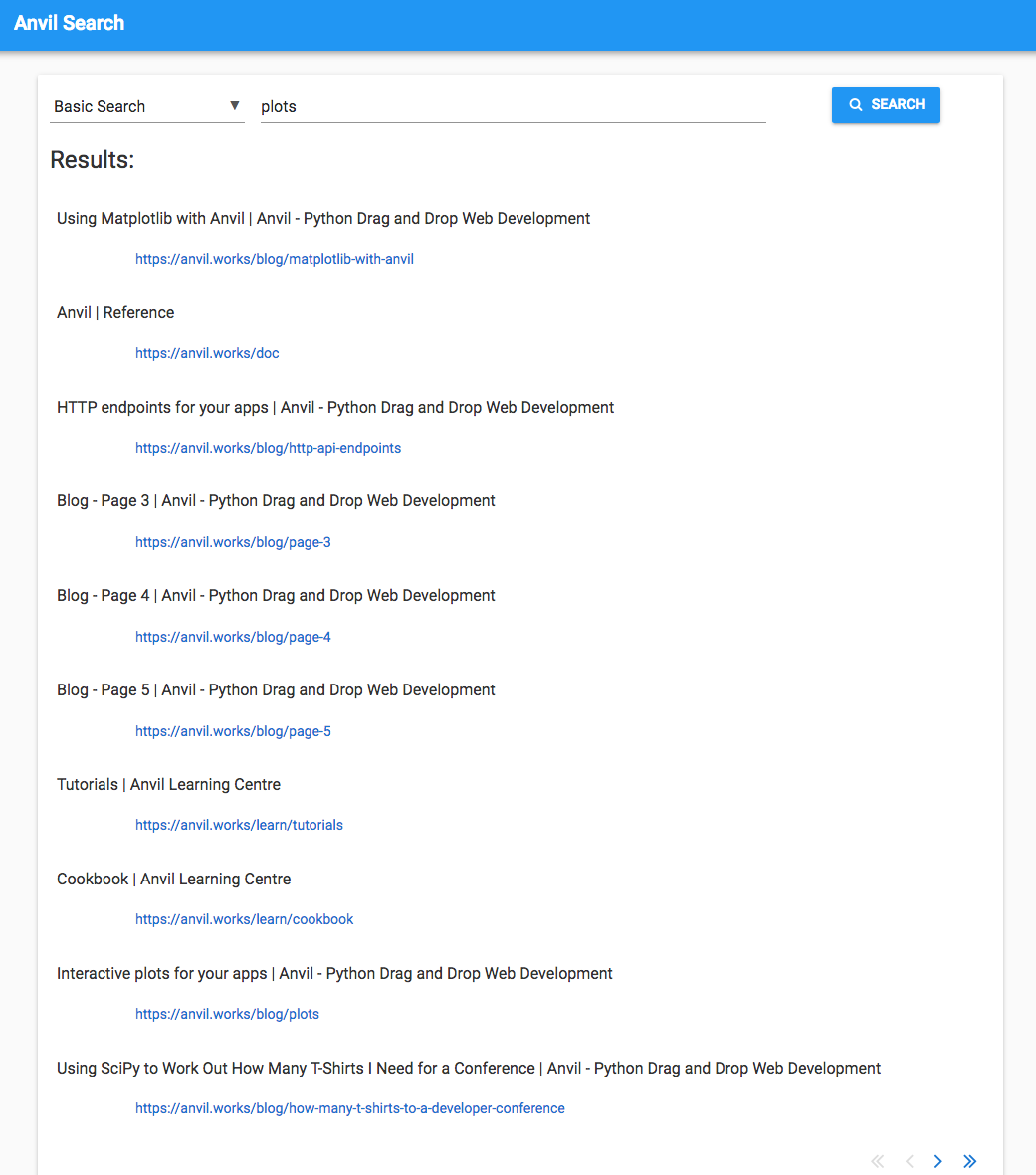
The first result is Using Matplotlib with Anvil, which is definitely relevant. Then there’s the reference docs, which has a section on the Plot component. And result number nine is the original announcement dating back to when we made Plotly available in the client-side Python code.
But there’s also a lot of fairly generic pages here. They probably mention the word ‘plot’ once or twice, but they’re not really what I’m looking for when I search for ‘plots’.
‘Uplink’
‘Uplink’ differs from ‘plots’ because it’s unlikely to be used by accident. It’s the name of a specific Anvil feature and it’s not a very common word in normal usage. If it’s on a page, that page is almost certainly talking about the Anvil Uplink.
If you’re not familiar with it, the Uplink allows you to anvil.server.call functions in any Python environment outside Anvil.
So I’d expect to get the Using Code Outside Anvil tutorial high up the results list. It shows up at position four.
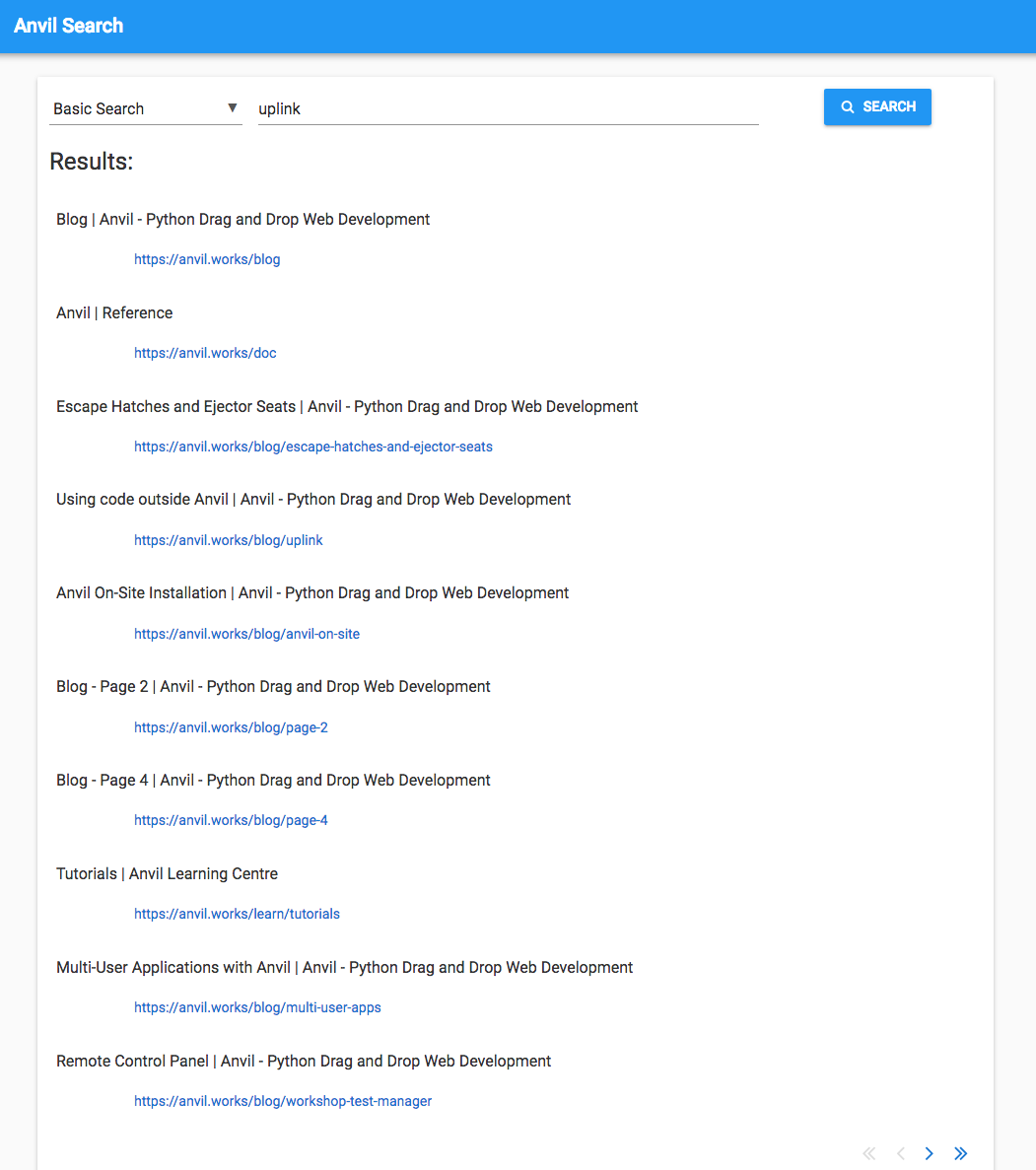
I also get Escape Hatches and Ejector Seats, which mentions the Uplink as one of Anvil’s ‘Escape Hatches’. And at number 10 we have Remote Control Panel, which uses the Uplink to run a test suite on a remote machine.
It’s good that all three of these show up, but it would be better if they were more highly ranked. The rest of the results probably talk about the Uplink in some way, but the Uplink is not their primary subject.
‘Build a dashboard in Python’
This is included as an example of a multi-word query. I’d expect this to be harder for the search engine to cope with, since the words ‘build’ and ‘Python’ are going to be used a lot on the Anvil site, but a user typing this in is specifically interested in Python dashboarding.
There are two pages I would expect to see here: Building a Business Dashboard in Python and the Python Dashboard workshop. Neither of these appear in the results.
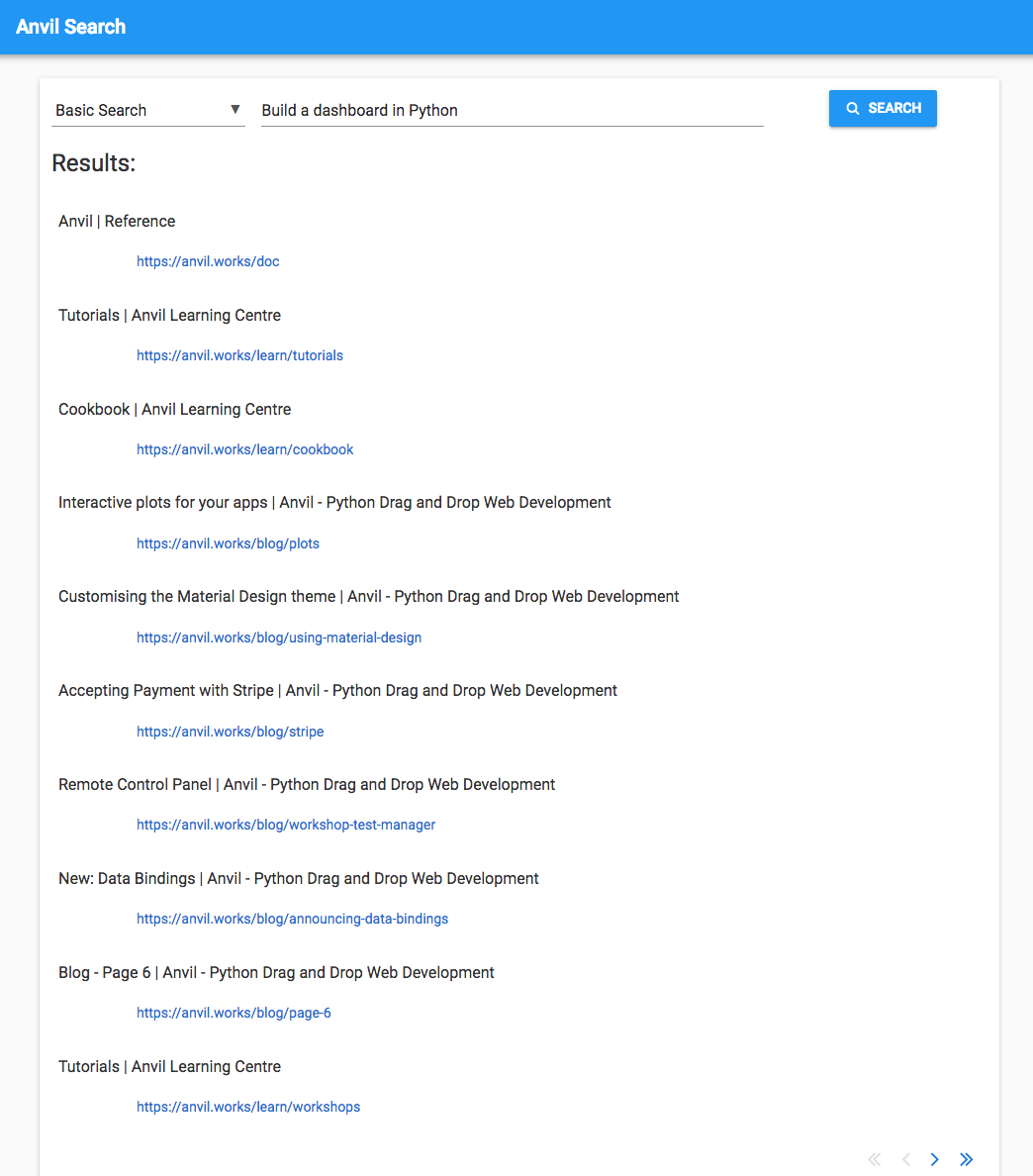
A few of the pages are tangentially related to dashboard building, but generally the signal appears to have been overwhelmed by the noise introduced by the words ‘build’ and ‘Python’.
So how did it do?
The basic search engine I’ve put together does manage to get some relevant results for one-word queries. The user has to look past the first few results to find what they’re looking for, but the main pages of interest are there somewhere.
It gets confused by multi-word queries. It can’t distinguish very well between the words that matter, and those that don’t.
Anvil’s full_text_match does remove words like ‘a’ and ‘in’, but it obviously won’t guess that ‘build’ is less important
than ‘dashboard’ in this particular situation.
Next steps
I’m going to make two improvements in an attempt to address these problems. First, I’ll try to rank more interesting pages more highly. Google has an algorithm called PageRank that assesses how important each page is, and I’ve always wanted to learn how it works, so now is probably a good time! I explore it and implement it in the next post.
Second, I’ll take account of the number of times each word appears on the page. This will help with the ‘building a dashboard in Python’ query, because pages that just happen to mention ‘building’ will do so once or twice, whereas pages about building dashboards will use those words a lot. That gives me an excuse to explore two simple but powerful concepts from Computer Science - tokenization and indexing, which I implement in the final post.
Implementing PageRank
So here goes, I’m digging into Google’s PageRank. It’s surprisingly simple; you might even say it’s ‘beautifully elegant’. Come read about it:
Or sign up for free, and open our search engine app in the Anvil editor: